
Designing Real-time Reports from S3 Data
At Gamesight, we build real-time dashboards so game developers can monitor social activity for their game. Here we compare the different architectures we evaluated for generating reports from data that we have stored in S3.

At Gamesight, we build real-time dashboards so game developers can monitor social activity for their game. To power these dashboards, we have multiple data pipelines monitoring gaming content on platforms like Twitch, YouTube, and Twitter. Since live streams are an important data source, our reports need to update with new data as it comes in.
The data we collect is stored in S3. Our challenge when creating dashboards was taking the existing data in S3 and running reports against it in near real-time, all while keeping costs low.
In this post, we'll cover the three approaches we considered for running analytical queries against data in S3, pros and cons of each, and how we ended up settling on the Redshift-backed approach we currently use.
Jump To:
Athena
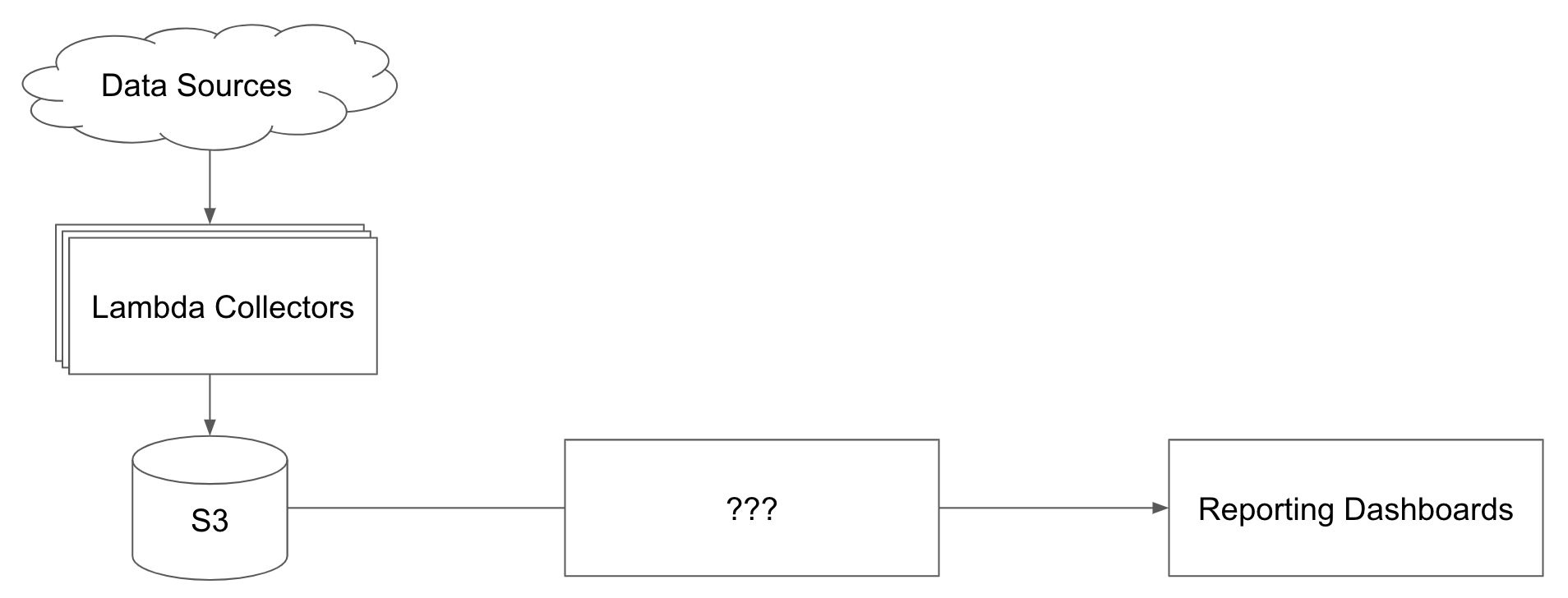
The first solution we looked into was directly querying our data in S3 using AWS Athena. Athena is a purpose built serverless tool for running SQL queries against data stored in S3. Looking at the marketing page it seems like the perfect solution - large scale queries directly against S3 "delivered in seconds." The billing is straightforward at $5/terabyte of data scanned.
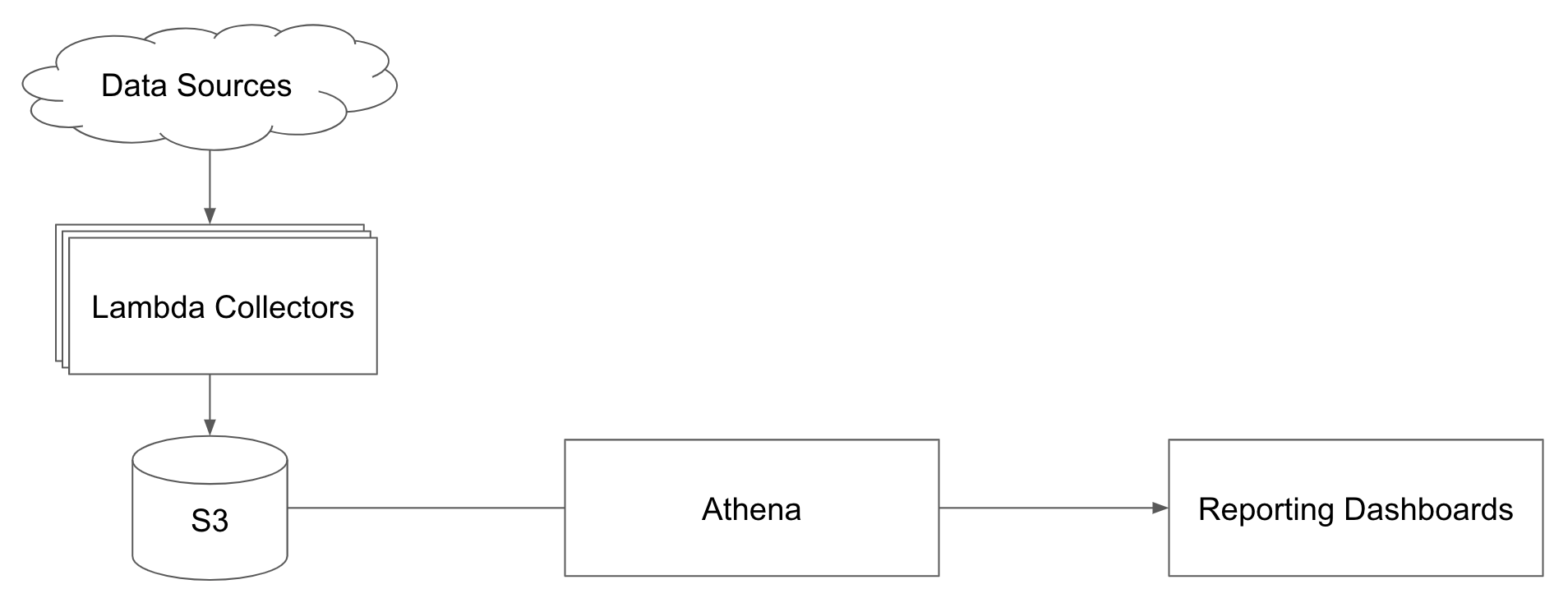
Using Athena to directly query data from S3
In practice, we found out that Athena latency can be several minutes when your queries involve aggregating terabytes of data. There were also downsides from a cost perspective. Since Athena recalculates results from S3 for every query, repeatedly running the same queries can become expensive.
We attempted putting a cache in front of Athena to address these issues but we still needed to to compromise on performance, cost, or data freshness. Athena was easy to setup and use, but it was too slow to power the dashboards for our application.
When to use: Athena is great for ad-hoc queries, especially when you don't have regular query patterns against your data. If you want to run the same query repeatedly, like when powering end-user facing reports, you might need a faster and more cost effective solution. We still regularly use Athena at Gamesight for ad-hoc data exploration.
AWS Glue & ETL
Next, we looked to a more traditional ETL architecture with AWS Glue. ETL is a generalized approach to copying and aggregating data between datastores. It includes three steps:
- Extract: Read data out of the source system. In our example case, read from S3.
- Transform: Apply a function to the extracted data to prepare it for storage. For Gamesight's dashboards, we aggregate our data in summaries, like "streams per hour".
- Load: Insert the transformed data into the target datastore.
We spent some time looking into ETL architectures that use Map Reduce tools like Hadoop or Spark. We used Glue, a serverless managed Spark service from AWS, for our evaluation.
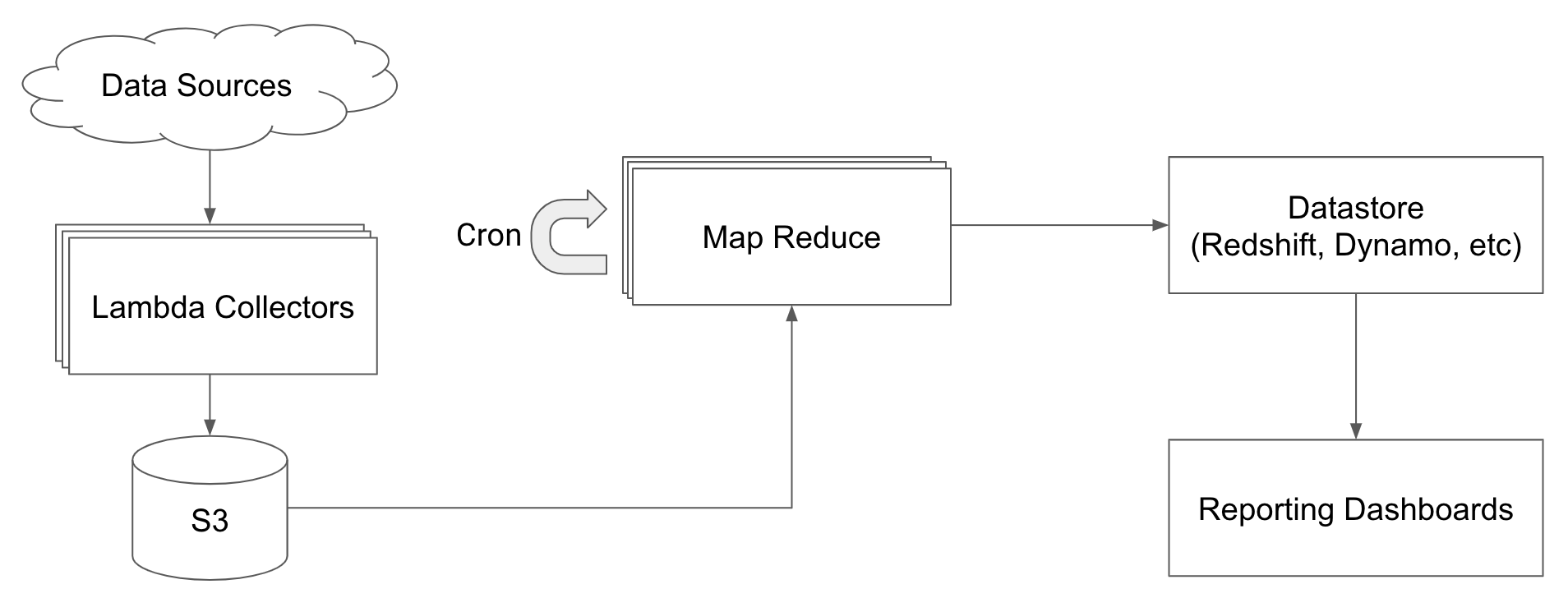
Using a Map Reduce framework to transform our data
The minimum billing duration for Spark jobs run in Glue is 10 minutes. This is problematic for our workload since the majority of the job powering our real-time reports are small batches that only process new data. Our short running jobs regularly execute in 1-2 minutes so we were overpaying by more than 80%.
In the end, the cost for running Spark with Glue was too great for our workload. We needed a solution that can do micro batches of data continuously. The Spark ecosystem is better suited for large batch jobs. And so our search continued.
While we prototyped ETL workflows, we also evaluated multiple datastores to hold our transformed data. During this evaluation we came across AWS Redshift, which led us to our next (and final!) approach.
When to use: Tools like AWS Glue and Spark are great for large scale data transformations. All of that power comes with additional tooling and complexity. If you are a small team or looking to run short transforms frequently, there are more cost effective solutions. The ecosystem is extremely rich, which is a plus if it does make sense for your workload.
Redshift & ELT
Redshift is a managed data warehousing solution from AWS. A data warehouse is a database that is optimized for reporting and analytical processing (compared to transactional databases like Postgres). We ended up applying a process that puts more of the burden of data transformation into the data warehouse known as ELT (Extract, Load, Transform). We load raw data from S3 into Redshift and do the majority of transformations there.
To handle the EL steps, we use SNS to trigger Lambdas when data is written to S3 [1]. These Lambdas extract row level data and write formatted rows to Kinesis Firehose which loads them into Redshift. Using serverless components for our extract and load steps takes operational burden like scaling and maintenance off of our plate.
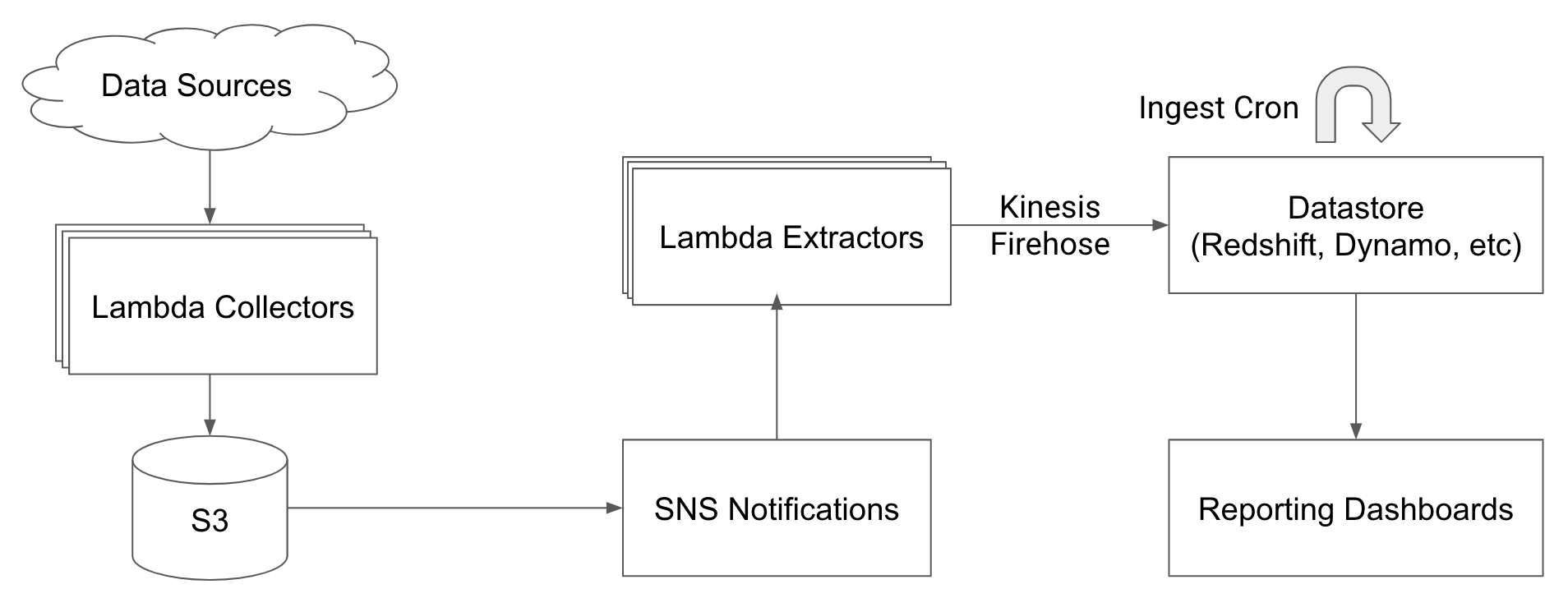
Simple Lambdas extract and load data and transforms occur in Redshift
Data ingest queries in Redshift run every few minutes and take raw records from Firehose, aggregates them, and saves them into summary tables for reporting. Redshift does most of the heavy lifting rather than an external data processing system. Some key benefits we have seen with the ELT architecture:
- Simplicity: Since data transformation and querying are both done through the warehouse, we don't have to manage dedicated infrastructure for transforming data like with AWS Glue. This frees up our team to focus on becoming experts in Redshift rather than splitting our efforts between Redshift and Glue.
- Flexibility: Having raw data available directly in Redshift allows us to create new aggregations without needing to go back to source data.
- Performance: Redshift safely and reliably handles distributing our queries across multiple nodes using the familiar transactional pattern of SQL.
We have been using this solution in production for over a year now. It has continued to be stable even as our pipelines have scaled up over time to processing billions of records a week. The near real-time nature of the data loads gives us access to fresh data quickly. We can adjust our Redshift ingest frequency so aggregates are available for end users.
When to use: If you are looking to take a more agile approach to your data pipelines, ELT provides a middle of the road solution that allows you to balance performance, flexibility, and cost. With less tooling and infrastructure to manage, you can focus more on higher value areas, like manipulating your data.
Gotchas
The ELT approach has worked well for Gamesight, but it isn't without its own drawbacks:
- SQL transforms can be complex: Writing transformations in SQL can be difficult. Trying to understand a 500 line SQL query can quickly cause your head to spin. We have found that following common query patterns and adding lots of comments helps ease this pain.
- Kinesis throughput limits: Kinesis doesn't have autoscaling throughput limits, so it is possible to hit max throughput at the Load step. It is easy to request limit increases, but you need to be vigilant and monitor throughput to avoid hitting your limits.
- Historical backfill is not free: When we create new pipelines, we often want to backfill historical data from S3. This isn't straightforward when data is loaded into Redshift through SNS notifications. We created a tool to handle data replay, which you can check out on Github.
- Specialized datastores: Redshift has a relatively high overhead when executing new queries (it can take multiple seconds to generate a new execution plan). We use a combination of Redshift, Elasticsearch, and Postgres to serve data to our products so that we are always querying from the best datastore for the job.[2]
[1]
It is worth noting that it is also possible to directly trigger Lambdas on new object creation in S3 without the SNS layer. The upside of using SNS is it allows us to kick off multiple transformations on a single file with fan out.
If you are planning on implementing a pipeline utilizing this S3-to-SNS-to-Lambda structure it is vital (for your own sanity) that all of your transform lambdas are idempotent. This is an important feature of a stable data pipeline since it allows for regular re-processing of data without having to worry about precise time boundaries or the effect data order will have on your system.
[2]
While Redshift is incredible for running analytical queries across billions of rows, it's a poor choice for simple operations like lookups by an ID. We have adopted a model of syncing data from Redshift into specialized datastores when our application demands different performance characteristics. For example, we keep copies of our content creator profiles in Postgres (using dblink) to handle fast lookups by ID. Additionally, we use Elasticsearch to power our search feature which is great for quickly providing the most relevant results to full text searches.